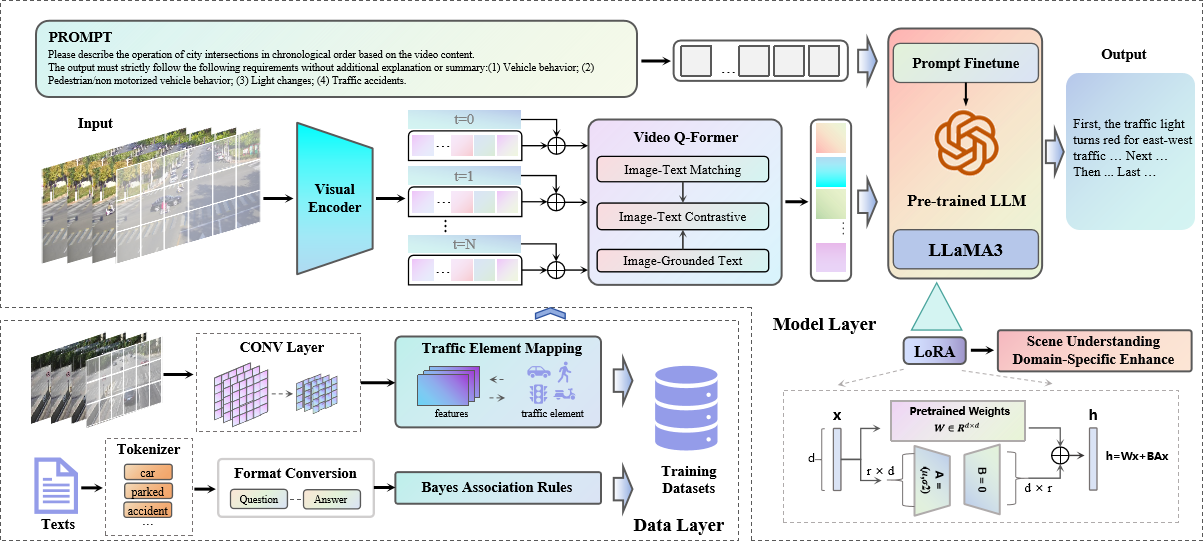
This paper proposes a method to perceive the state of the entire road network for MFM-based traffic scenarios. First, a structured semantic annotation approach is employed for video-image labeling, coupled with traffic video datasets to construct a multi-modal road traffic dataset. The videos and corresponding annotations are fed into the model. A video Q-Former extracts spatiotemporal dynamic features from the videos and aligns visual features with textual information. Finally, the aligned joint features, combined with prompt text, are input into a pre-trained LLM, which outputs traffic scene comprehension text. To further adapt the framework to roadside monitoring scenarios, we implement a traffic scenario-refined fine-tuning strategy using Low-Rank Adaptation (LoRA). Through end-to-end multi-modal alignment and lightweight optimization, this framework provides a high-precision, low-latency, and interpretable traffic scene understanding solution for road network state perception.


